Cracks / pops in sound when using sf3
I think it has already been pointed out in other older posts that sometimes the sound exhibits random or periodic cracks when using the new sf3 soundfont.
I think I found the origin of these noises.
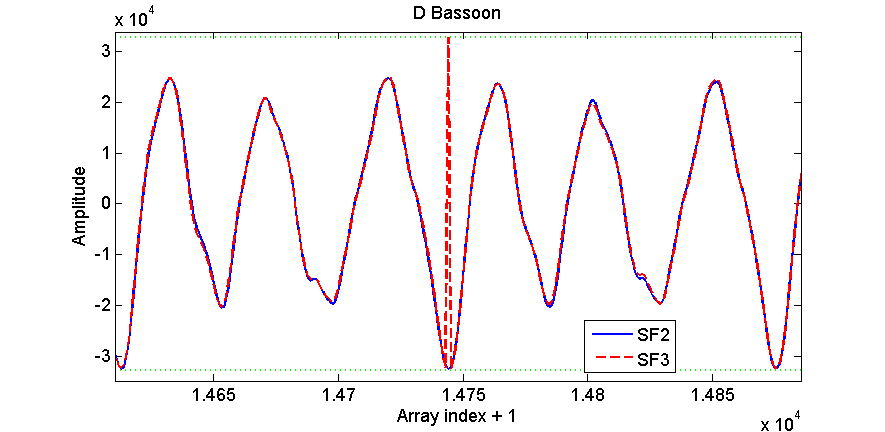
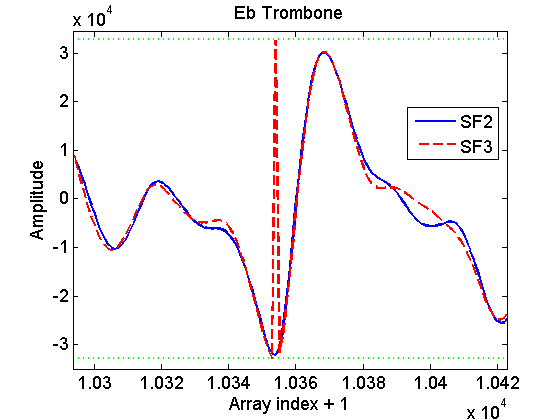
In attachment are two examples. The basson one exhibits one clear pop during playback with FluidR3_GM2-2.sf3. The example with trombone is definitely worst: the note sounds ruined.
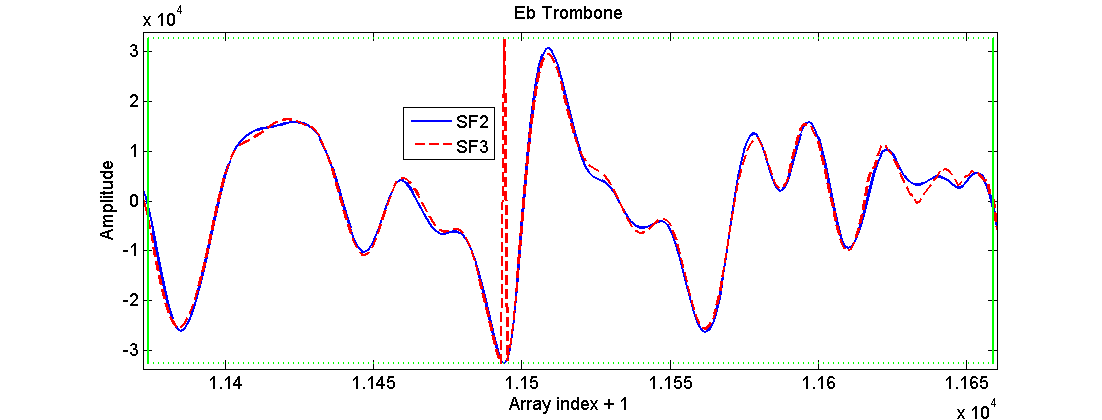
The problem is shown in the three png figures. These figures show details of the waveform of the samples which MuseScore uses for playing these notes, in the FluidR3_GM2-2.sf2 case (continuous blue line) and FluidR3_GM2-2.sf3 case (red dashed line).
In the sf3 sample for the bassoon there is a one-point peak in the waveform before entering the loop of the soundfont.
In the sf3 sample for the trombone there are two points showing this single-point peak: one before the beginning of the loop (EbTrombone.png) and one inside the loop (EbTromboneLoop.png, where the loop boundaries are shown with vertical continuous green lines). That's why the note sounds completely ruined.
By looking at the waveforms, these peaks seem to be due to integer overflow for short integers at the lowest boundary (the boundaries are shown as green dotted lines in the figures).
For both cases the corresponding value for the sf2 case is within the [-32768,32767] interval. I didn't know how to check the pure sf3 case (i.e. from the sf3 file alone) because I don't know how to handle the vorbis compression. The sample in the figures were taken when MuseScore had already loaded from the soundfont and worked with the samples (in particular, I put a printf of the sample data at line 1484 of fluid/voice.cpp), so I don't know if they are already present in the sf3 file or if they are generated by other operations occurring after loading.
| Attachment | Size |
|---|---|
| trombone_sound.mscz | 1.29 KB |
| basson_sound.mscz | 1.27 KB |
| DBassoon.png | 11.56 KB |
| EbTrombone.png | 7.8 KB |
| EbTromboneLoop.png | 11.49 KB |
{kind=link}
{kind=link}
{kind=link}
Comments
I've already postulated with the one I've come across that the conversion to Ogg is responsible.
Without more testing it is hard to say why this is happening.
I have noticed that there tend to be artififacts in some of the Fluid Samples -some of them are not as clean as they might be, and my theory is that the Ogg conversion process is somehow picking these up and amplifying them.
I need to do much more testing before I can narrow this down however.
I may have just found something significant regarding this problem in Wikipdia's article on Vorbis compression:-
Characteristic artifacts
As with most modern formats, the most consistently cited problem with Vorbis is pre-echo, a faint copy of a sharp attack that occurs just before the actual sound (it commonly cited that this artifact is most obvious when reproducing the sound of castanets).
When the bitrate is too low to encode the audio without perceptible loss, Vorbis exhibits an analog noise-like failure mode, which can be described as reverberations in a room or amphitheater. Vorbis's behavior is due to the noise floor approach to encoding; see technical details.
The full article is to be found here: https://en.wikipedia.org/wiki/Vorbis
This seems to support my suspicion that artifacts introduced by the Vorbis compression are somehow being picked up and amplified by the Fluid sound engine.
Yesterday evening I had some time for experiments, but I still can't understand if the short integer overflow happens at encoding time (i.e. when the sf3 is created), or decoding time (i.e. when libsndfile loads the sample), or possible post-processing.
In principle at encoding time the sample is converted to float and renormalized, so the problem should not be there. I tried to play with libsndfile sf_command (with options SFC_SET_CLIPPING, SFC_SET_SCALE_FLOAT_INT_READ) but I didn't see any difference.
I managed to avoid the "clicks" during playback by increasing by ~5% the normalization value in the sf2->sf3 conversion, but this is not the proper solution (it also reduces by ~5% the full dynamic range of the sample).
@ChurchOrganist: Can you try to play the files in which you were hearing artifacts with the following sf3 SoundFont?
https://docs.google.com/file/d/0BxjayMZiuupOWXpXU0NqUFN4dm8/edit?usp=sh…
This is the 5%-corrected SoundFont I am mentioning above (and zipped with 7zip). I would like to check if these artifacts are the same that I hear or if the chain vorbis-compression / decompression / playback does introduce other effects I have not yet stumbled upon.
In reply to SoundFont test by ABL
There are no audible artifacts when using the 5% corrected soundfont you gave me a link to.
I still have a suspicion that the root cause of this is the poor quality of the original samples in the Fluid soundfont of which many are extremely gritty. I was actually quite shocked by the quality of some of them.
If I get time it might be interesting to clean them up with noise reduction software and see if that makes a difference - if I can persuade my ancient Sony plugins to work with the new version of Sonar.
I'm too involved with tweaking Aeolus and the Instrument Llist ATM however to expect to even start on that before the end of the summer at the earliest.
In reply to There are no audible by ChurchOrganist
Thanks for the tests. I will thus continue to experiment in order to pin down the exact lines where the artifacts appear (and hopefully patch them).
If this may help, I found a free software for sf2 editing: Polyphone - http://polyphone.fr
It seems useful: I used it to double-check the original sample of trombone and bassoon I extracted from MuseScore.
In reply to Thanks for testing by ABL
Thanks - I'll take a look, but I'm pretty locked into the way Viena works now :)
In reply to Thanks for testing by ABL
The good things about Polyphone are that it's still under development, it's open source and it's C++/Qt. So SF3 support could be built in :) I talked about it here http://musescore.org/en/node/20496
In reply to SoundFont test by ABL
FWIW, I had reported this same issue recently as #21814: Playback of SF3 features loud pops. The modified soundfont posted here eliminates the pops in my tests with acoustic bass as well.
In reply to SoundFont test by ABL
@ABL Thanks for creating this file! Sounds much better without those snap, crackles and pops.
libsndfile is taking forever to release
In reply to ty ABL by activedecay
Yes, and I wonder if we should really be depending on that. Is this a problem mostly in FluidR3 or is it common with other soundfonts? I like FluidR3 personally, but I know some have misgivings about it, and am wondering if we should be thinking about a Plan B. Well, actually, as far as I am concerned, releasing MuseScore 2.0 with the 5%-compressed FluidR3 works for me as Plan B, but perhaps there could also be a plan C.
Not that I have any particular recommendations. The effort to develop our own in-house soundfont is still interesting long term, but I don't think that is a viable 2.0 option.
In reply to Yes, and I wonder if we by Marc Sabatella
Let me finish converting all the instruments to mono so they can be set properly in the stereo soundstage before we make a decision.
In reply to Yes, and I wonder if we by Marc Sabatella
I've been using the Sonatina Soundfont myself. I think that many of the sounds are more realistic than Fluid. The major downside is that it is just standard orchestra sounds which is rather limiting.
In reply to Another Potential SoundFont by peter.frumon
One could certainly build a GM-compatible soundfont by taking Sonatina for the instruments where possible then filling out the rest from Fluid or elsewhere. That, from what I understand, how a lot of these soundfonts were built in the first place. But FWIW, I have mixed feelings about Sonatina as well. The demo sounds good, but when I actually try it out, it's not an obvious improvement to me. Not that the samples themselves aren't fine, but MuseScore is still limited by the fact that it always uses the same sound for each instrument regardless of articulation. Eg, winds slurred versus tongued, strings taken on one bow versus bowing each note individually, etc, as well as the lack of ability to shape notes after attack. It's possible Sonatina supports these somehow, but MuseScore can't take advantage of those features if so.
In reply to One could certainly build a by Marc Sabatella
It would certainly be possible to build a soundfont which responded to articulation changes.
It would merely be a case of using velocity splits to change the attack on the note.
MuseScore would, however, have to stop misusing velocity for dynamic changes in continuous tone instruments.
As this represents a change in the current sound architecture then I guess that would be something for the next rewrite.
In reply to It would certainly be by ChurchOrganist
If I'm understanding you correctly, I don't think what you're saying works.
Velocity isn't "misused" for dynamics on instruments like trumpet, etc - it really is the proper way to capture the *initial* dynamic. For any given articulation - say, a tongued attack on trumpet - it's possible to do it loud or do it soft, and it isn't just a question of turning up the volume. The actual sound of the attack changes. So velocity switching is the standard mechanism for this. Higher velocities are louder but *also* give the harshes attack. Volume controller would only be used to change the overall volume of the track (mixer-style) or to simulate crescendo/diminuendo after attack (although this too shouldn't really be *just* a volume change - tone changes too).
Anyhow, there is no way I can see to shoe-horn the different articulations in via velocity switching - velocity *does* have to be used for attack volume, and switching is normally used to select different attack samples, but all within the same basic articulation (tongued). Instead, my understanding is it's the *legato controiller* that is supposed to be used to enable to switching of articulations. Or at least, in the specific case of tongued versus slurred, or notes on a single bow versus a bow change. There might be other ways of implementing this, such as having separate "tongued" and "slurred" patches for each insturment and having MuseScore automatically switch between them as appropriate. But velocity shouldn't be the mechanism, because then there would be no way to also change the character of the sound *within* the world of tongued notes, and that's at least as important.
In reply to If I'm understanding you by Marc Sabatella
You've totally misunderstood Mark.
In an instrument such as a trumpet there are a number of stages in the amplitude envelope of a given note. Put at their simplest level (they're actually far more complicated) the equeate to Attack, Decay, Sustain, Release - what is known in the synth world as an ADSR enevelope.
The initial stage of the amplitude envelope, is controlled by Velocity - this is NOT the same as Volume - Volume is as you quite rightly say for setting channel volumes.
The player, once (s)he has initiated the note then has complete control over the volume by means of breath pressure, and can make the dynamic louder or softer at will. In the synth world this is achieved with MIDI controller 11, known as the Expression controller.
So in a synthesised trumpet you would use Velocity to control attack, using velocity layer splits to achieve the degree of attack you require ranging from 127 for sFFz to 0 for a slur. The expression controller is then used to control the dynamic ranging from 0 (silence) to 127(fff).
You can of course then control the pitch envelope with the modulation controller to produce varying amounts of vibrato.
One of the big problems with most GM soundfonts, and FLuid is no exception in this is that all the instruments have a predefined amount of vibrato which kicks in usually much too soon after the note is initialised.
So if we are to produce a realistic trumpet sound in MuseScore we would need to have a soundfont which has the ability to select one of a number of predefined velocity layers determined according to the amount of attack required, and then to control the succeeeding amplitude (dynamic) of the note useing the Expression controller.
I will have to dig out some of my backing track master files for you to look at to see how this is achieved.
In reply to You've totally misunderstood by ChurchOrganist
Hmm. I think you're right that I misunderstood you, but only partially (I hadn't considered the possibility of using velocity=0 to mean slur - see below). The real issue here is that we seem to have very different experiences that shape our notions of how things should work. So let me explain where I am coming from, as I really would like to reach an understanding here so we are agreement over how to move forward.
First, I actually do know about ADSR envelopes and so forth - my first synth experiences were from the additive & FM days - Yamaha DX-7 etc. And I used to write low level code that dealt with the MIDI messages directly, so I was quite familiar with how different synths formatted, sent, and received data. Unfortunately, my experience pretty much stopped not long after, so sample playback and General MIDI are still kind of "newfangled" to me except as black boxes (I plug in my digital piano, get something that sounds vaguely like a piano, and I'm satisfied). It's certainly possible and indeed quite likely that the world has changed since the 80's when my primary experience was formed, plus my memory isn't what it used to be. :-)
Anyhow, in my world, the overall volume of a note was controlled by velocity, period. Yes, you could optionally assign a wheel or other control to raise or lower the volume after the attack, but a note with high velocity had a loud attack *and* a loud sustain, and a note with a low velocity has a soft attack *and* a soft sustain, assuming you didn't explicitly override this with the volume controller. If you didn't touch the wheel, no volume messages were sent. All that got sent when you pressed a key was a note-on message with a given velocity, and that controlled the volume of the attack as well as the volume of the sustain.
As I said, velocity always affected both attack and sustain. Really fancy synths also supported a velocity parameter on the note-off message (eg, how fast you let up on the key) that could affect release. But actually, many of the synths I dealt with not only didn't send release velocity info - they never sent true note-off messages at all. Instead, they sent note-on with velocity=0. That was a standard synonym for note-off back in the day.
If a synth supported velocity switching, it might affect the attack or the sustain volume levels or both (or something else), but it did not ever in my experience change the *nature* of the attack from tongued to slurred. There is, after all, a difference between a quiet tongued note versus a slurred note, or a loud slurred note versus a tongued note. And in a world where velocity is the main determinant of volume, you wouldn't be able to have soft tongued notes or loud slurred notes if velocity switched the sound between slurred and tongued.
You mention using note-on, velocity=0, to indicate a slurred note, and that's a clever enough idea that I can easily believe got implemented by someone at some time since my experience ended in the 80's, but in the 80's, velocity=0 meant note-off. If you wanted a slurred note, you either switched to a different patch entirely, or used the legato controller and hope your synth implemented it well.
So there are several places where my understanding of MIDI differs from yours:
1) In my experience, volume controller messages are never used (or needed) to control basic volume of a note. Velocity controls the volume of sustain just as surely as it does attack. Are you saying that today, this is no longer the case, and that note-on velocity is meant to affect attack only, and that it is standard for synths to send volume messages along with each note-on (or perhaps with each change of velocity) to control the volume of sustain?
2) In my experience, note-on with velocity=0 is completely equivalent to note-off. I don't know if that was just convention or if it was written into the standard, but it is the way most synths I dealt with worked. Are you saying it is now standard for synths to interpret velocity=0 as meaning, "play note with no attack" (and presumably use volume controller to set sustain level)?
I could easily imagine things working as you seem to be describing, but it's quite different from what was once the case. I'm perfectly willing to be educated here, if you want to point me to some relevant documentation. The idea of using velocity to only affect attack volume but then automatically send a volume message seems totally workable to me - but also totally foreign to my experience.
In reply to Hmm. I think you're right by Marc Sabatella
Of course, what you are describing here is the control of synths from a keyboard, where indeed running status usually determines that a velocity of 0 is a note off.
There are other ways of controlling a synth. The way I did it in my backing track programming days was to program a sequencer to implement the required controller changes. I was using 4 XG synths for this which meant that I had direct control over the amplitude envelope through SysEx messages anyway, so I had no need to use velocity in this way. But samplers were just becoming more prevalent when I stopped (around 2000) and they were using velocity in this way (although I'm not sure about Velocity 0).
There is also the Yamaha WX7 controller with which you use breath and lip pressure to control the synth.
To address your points:-
1. You keep talking about the volume controller, and as I keep saying the volume controller (#7) is not used for real time control of dynamics, but simply for setting channel levels. It is the Expression controller (#11) which is used in this way. What I am saying is that for wind brass and string instruments velocity is not the natural controller of dynamic. In a real instrument breath pressure (or bow in strings) is what controls the loudness of a note. The tongue controls the attack (speed of bow). Obviously it is a more complicated relationship than this, but in terms of controlling samplers it is the logical way to think. So the level of velocity determines which articulation sample is used, and then the expression controller is used for loudness. Not the same degree of control as you would have with a real synth, but with enough velocity splits can be very realistic, which is why Fluid sounds better than TimGM6MB. So this would enable a proper sffz to be performed with a fortissimo attack dropping immediately to piano or even pianissimo.
With percussion, plucked instruments and pianos velocity would still be used to transmit dynamic information, as that is the natural means for these instruments to control loudness.
2. I had actually forgotten about running status, and so Velocity 0 could not be used for slurs, but a velocity of 1 could, or the portamento controllers could be used, although that is rather fiddly to set up IME.
I think the difference is that your experience has been with synths that actually generate their own sounds, in which you have direct control over the many parameters of the sound. In the case of samplers - which is what a soundfont is - slightly different techniques need to be used to achieve the same results.
The means to set up an instrument as responding to the expression controller is already there in the instrument.xml DTD using the <controller> tags. We would just need to alter the way MuseScore operates dynamics for continuous tone instruments.
I would suggest that this would be done by means of the user specifying this behaviour as part of the score setup, the default being the usualy velocity driven dynamics.
Hope this makes things clearer.
In reply to Of course, what you are by ChurchOrganist
Good point about the difference in the synths we are familiar with, and of course you're right that I keep not getting that you are talking about expression and not volume.
All I can say is, what you say makes sense - I could imagine things working that way. I've just never seen it. Would love to see some documentation on this to study. In particular, on how wind instrument controllers actually structure their data. I have only an el cheapo casio toy midi saxophone, which to my recollection uses the simple note on / note off model, no controllers.
FWIW, since I've been looking at the code that generates sustain pedal events, I decided to try a quick-and-dirty implementation of slurs using legato controller. I *think* I was sending the messages correctly. But it seems fluidsynth is ignore them (or perhaps code deeper in MuseScore was rejecting them since it wasn't designed to handle these messages). Bummer, I was actually hoping for a minute there it would be easy to sneak this in.
Unfortunately, the problem lies in the decoding by libsndfile.
By using the old implementation of sf3 decoding (which however was not working in Mac because of memory problems) the playback doesn't exhibit artifacts.
I also found references to this problem of libsndfile:
https://github.com/erikd/libsndfile/issues/16
https://github.com/LaurentGomila/SFML/issues/310
http://thr3ads.net/vorbis/2013/01/2167519-Whats-the-value-range-of-floa…
In particular, lossy encoding can create values outside the range [-1,1) in decoding which then cause overflow when multiplied by 32768 (or 32767) and translated to sort integers.
I tried with SFC_SET_SCALE_FLOAT_INT_READ or SFC_SET_CLIPPING but they don't seem to work in this case.
One possible (ugly) solution could be a rinormalization at encoding time simlar to the test soundfont I created and posted here. This however requires to guess which will be the maximum value of the decoded new samples (by using the old sf3 read implementation and making MuseScore write down all values outside the [ -32768,32767 ] range it seems that +-34000 is never reached and exceeded; for the test sounfont I used 34768.f as renormalization, which is roughly 6.1%).
Another possible solution could be to read the samples as floats and then renormalize and convert to short integers, but in this case the approach is similar to the old implementation (which directly used ogg and vorbis routines to read the samples) and the old implementation had problems in Mac.
In reply to libsndfile by ABL
Is libsndfile still under development?
In reply to Is libsndfile still under by ChurchOrganist
@ChurchOrganist: Yes.
The SFC_SET_SCALE_FLOAT_INT_READ not working for ogg should be solved in libsndfile 1.026 (but I have not tested it yet); one possible problem could be the time spent for computation, according to this https://github.com/erikd/libsndfile/issues/16 (first comment of LaurentGomila), but maybe in our case the additional time is not so long (hopefully).
According to this http://comments.gmane.org/gmane.comp.audio.libsndfile.devel/420 a stable release of libsbdfile 1.026 should be arriving soon, considering also the fact that the new version of flac mentioned in the same answer there was released on 1st June (see https://xiph.org/flac/ ).
Just guessing, but I think libsndfile 1.026 will be released before MuseScore 2.0 ;-)
In reply to libsndfile 1.0.26 by ABL
I tried with libsndfile1.0.26. First I tried with a build I made from source, but then I had to add to the installation the vorbis, flac and ogg dlls I had compiled; notwithstanding this, with the SFC_SET_SCALE_FLOAT_INT_READ it was working, as the following (simpler) procedure.
Then I found a pre-compiled 1.0.26 prerelease http://www.mega-nerd.com/tmp/libsndfile-1.0.26pre3-w32.zip
The zip file contains libsndfile-1.dll at version 1.0.26 (pre-release).
By then adding
sf_command(sf, SFC_SET_SCALE_FLOAT_INT_READ, NULL, SF_TRUE);at line 73 of audiofile\audiofile.cpp, so that the read function becomes:
int AudioFile::read(short* data, int frames){
sf_command(sf, SFC_SET_SCALE_FLOAT_INT_READ, NULL, SF_TRUE);
return sf_readf_short(sf, data, frames);
}
the sf3 soundfont is loaded and the sound no more exhibits cracks during playback.
(I don't know if this is the right position at which the sf_command should be placed; it can probably be set in a previous place of the sf3-loading chain)
In my system it does not seem to introduce evident delays in soundfont loading, however my laptop is almost brand new. More tests should be performed on older machines.
In reply to Good news by ABL
Hi
Should we create an issue for this?
In reply to Hi Should we create an issue by chen lung
There's already one by Marc Sabatella :-)
#21814: Playback of SF3 features loud pops
As of today, it seems libsndfile 1.0.26 has not been released yet, but as soon as it's done we can update the library (and the code with the sf_command) and the pops / cracks should disappear.
In reply to Good news by ABL
OK as mentioned further up the page here, the mono version of Fluid R3 is under beta testing.
After re-reading this thread it has become apparent that attenuation needs to happen at the Encoding stage for SF3, applying attenuation in the soundfont will not work.
We therefore need a version of ABL's tweaked version of the SF3 compression utility if we are to produce a normalised version of FluidR3. Is it available from your GitHub repository?
In reply to OK as mentioned further up by ChurchOrganist
Actually, my change was just a single-line change, i.e. I changed line 1232 of sftools/sfont.cpp
https://github.com/wschweer/sftools/blob/master/sfont.cpp#L1232
buffer[0][j] = ibuffer[i] / 32768.f;by substituting 32768 with a different number (34768 in my case).
This change is not expected to work in every case (the number I used is just a particular case that worked in our situation; maybe the modified soundfont will require a different number), and we are losing part of the dynamic range. That's why an upgrade of libsndfile to 1.0.26 would definitely be better.
Unfortunately, the creator/maintainer of libsndfile is continuosly delaying the release of the new version (he promised a release almost one year ago, but it has not happened yet).
As you can see in one of my previous post, the re-scaling at load time is working for the pre-release of libsndfile 1.0.26.
We could wait for the official release, or (if the license allows it) take the part of the code of libsndfile that we use and add them to MuseScore code (but I don't know if the license allows this and to what extent).
Compiling libsndfile under MinGW in Windows seems not to allow the creation of a single dll; for a single dll it has to be cross-compiled under Linux (with flac, ogg, vorbis static and libsndfile dynamic).
N.B: the sftools should be updated to the compilation with Qt 5.2.1 (under both Linux and Windows). I could make a PR (it simply requires the same change made to the main code for the compilation), but probably not before Sunday.
In reply to One-line change by ABL
libsndfile-1.0.26 is out since November 2015
Hi,
This thread is old but this is to tell you that the latest version of Polyphone (1.7) can export a soundfont as sf3. Different compression levels can be chosen, which should allow you to avoid looping problem resulting in pops.
Davy